AIが候補者と求人案件を自動マッチング。最も響く時にアプローチ
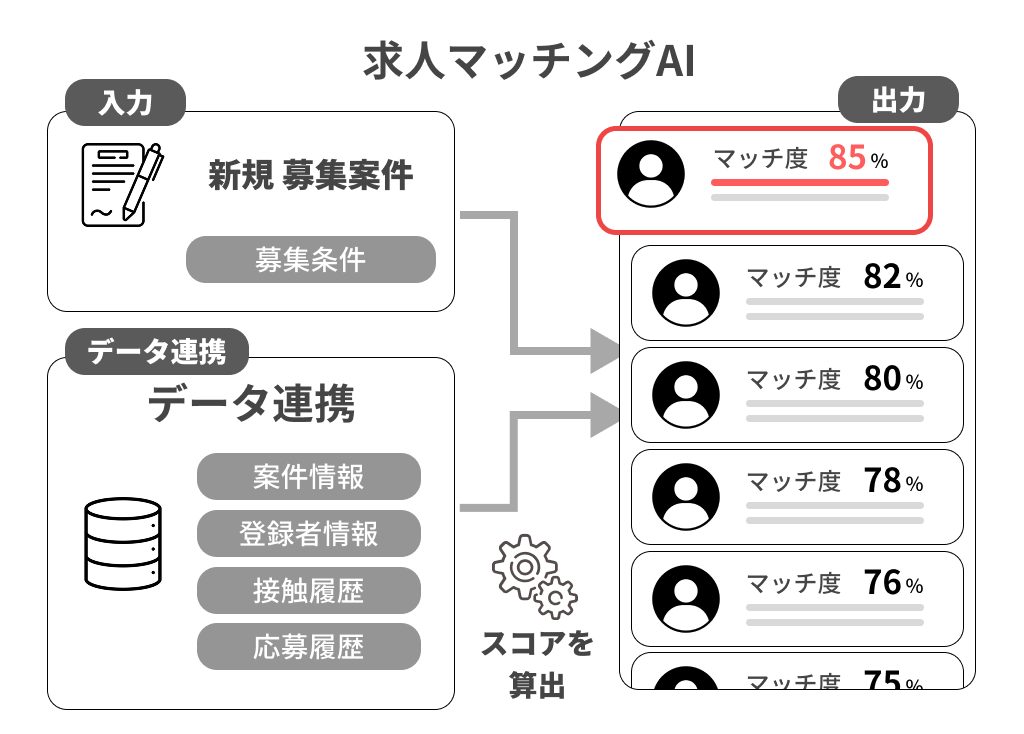
求人マッチング AIは候補者の登録情報と求人案件情報を統合し、AIによって適合度を算出し、マッチ度の高い順に検索・表示する、採用マッチング支援システムです。
登録者や案件情報、メール・電話・応募履歴、求人への反応データなどをもとに、関心が高まりやすいタイミングで有望な人材にアプローチ可能。
アプローチ対象の候補者の優先度が明確になり、採用活動のスピードと成果を同時に高めます。
既存の採用管理システムやCRM等のシステムと連携可能です。
採用は労力がかかるだけでなく、マッチングの機会を見逃してしまう
従来の採用活動では、求職者へのアプローチは担当者の経験や勘に依存し、「誰に、いつ、どの求人を案内するか」という判断に時間と手間がかかっていました。
しかし...
- 候補者の数が膨大で、誰から優先的にアプローチすべきか判断に時間がかかる
- 実際にアプローチしても連絡が通じないケースが多く、話が進まない
- メールや電話でのやり取り履歴が複数のツールや担当者の中に分散している
- アプローチのタイミングが感覚や経験に依存し、機会を逃してしまう
- 反応の見込みが低い候補者への連絡に時間を費やしてしまう
結果として、有望な人材への接触が遅れ、採用機会を逃すことが少なくありません。
有望候補者を瞬時に特定し、最適なタイミングでアプローチ
求人マッチングAIは、候補者データと求人案件情報を統合し、AI が適合度をスコアリング。
メールや電話での過去のやり取り、求人への反応履歴をもとに、今アプローチすべき候補者を優先度順に表示します。
- 電話・メールアプローチの優先順位を自動化
- 高い反応が見込める候補者を上位に表示
- 適切なタイミングでの連絡により、通話接続率・返信率を改善
- 有望候補者への初動スピードを加速し、採用成果を最大化
主な機能
求人マッチングAIの主な機能は以下のとおりです。
- 案件適合度スコアリング
候補者のプロフィール、過去の応募履歴、電話・メールでのやり取り履歴、求人への反応状況をもとに AI がスコア化。 - 優先度順表示
高スコアの候補者を一覧上位に表示。アプローチ対象を即座に特定可能。 - 電話・メールアプローチ支援
優先度の高い候補者の連絡先や過去やり取り内容をワンクリックで確認。即時アプローチを実現。 - 検索・フィルタリング
職種、勤務地、スキルなど条件で絞り込み、複数案件を横断的に確認可能。 - 既存システムとの連携
採用管理システム(ATS)や CRM と連携し、既存データを活用して導入コストを最小化。
導入事例
大手人材企業様事例 大手人材企業様では求人マッチングAIにより、従来の接触リスト作成業務を置き換えました。 従来、接触リスト作成にはベテラン人員が都度1時間ほど時間とノウハウを費やし、見込みのあるリストを作成していました。 求人マッチングAIは、その操作を数秒にするだけでなく、同じ架電総数170件でのビフォーアフター比較で、接触から成約までのファネル全体が大幅に改善することが検証されました。
| 段階 | 従来(経験ベース) | AI抽出リスト |
|---|---|---|
| 架電総数 | 170 | 170 |
| 接触 | 17件(10%) | 71件(41.8%) |
| エントリー | 2件(10%) | 22件(31.0%) |
| 成約 | 1件 | 6件 |
接触は電話での登録者へのアプローチ、エントリーは接触の結果エントリーにつながった数です。接触率もエントリー率も途中の通過点で、最後にどれだけ決まったかが本当の成果です。その成約が、従来の1件から6件へ、約6倍になりました。
この結果は一度きりではなく、7月の実証で接触率34.1%、翌8月の再実証で41.8%と、月をまたいで再現を確認しています。
本事例では、人力でリストを作成する際は、多くでも1-2種類の情報ソースを元に検討する一方、求人マッチングAIは5件以上のデータソースの情報を統合し、リストを選定します。 飛躍的な改善はある意味自然なものなのかもしれません。実証の詳しい内訳や、精度を上げる際の注意点はマッチング精度の改善事例にまとめています。
応用領域
求人マッチング AI は、単なる人材派遣・紹介業にとどまらず、「候補者と案件のベストタイミングでの接続」を必要とする幅広い業種で活用できます。
- 人材派遣・人材紹介業
大量の登録者データから、今すぐ稼働可能な人材を優先抽出 - アルバイト・短期採用管理
短期間の求人と直近稼働可能な登録者をリアルタイムにマッチング - 業務委託マッチングプラットフォーム
フリーランスや専門人材の稼働状況を常時モニタリングし、案件発生時に即提案 - 企業内異動・社内公募制度
社員のスキル・希望と社内プロジェクトの募集タイミングを自動で結びつけ
今後の展望
求人マッチング AI は、企業が有望な候補者を最適なタイミングで見つけ出し、素早くアプローチできる環境を実現します。これにより、求人発生から接触までの時間は数日から数時間単位へと短縮され、他社に先を越される前に動くことが可能になります。
同時に、求職者側にも「今まさに条件が合う案件」だけが届くようになり、不要な連絡が減り、検討すべき求人に集中できるようになります。
この双方向の最適化は、採用担当者の業務効率を高めるだけでなく、求職者にとってもストレスの少ない転職・就業活動を後押しします。結果として、ミスマッチによる早期退職や辞退が減り、企業には定着率の高い人材、求職者には長く働ける職場という好循環が生まれます。
今後は、応募前からマッチ度や条件が可視化され、「応募してから判断」ではなく応募前に納得できる採用の形が新たな標準となっていくでしょう。